В свете современных требований к преподаванию русского языка в качестве центральной единицы обучения рассматривается текст, в связи с чем целесообразно как можно шире использовать работу с текстом, отрабатывать навыки рационального чтения, обучать анализу текста.
Стратегии смыслового чтения, сформулированные ФГОС, включают в себя поиск информации и понимание прочитанного, преобразование, интерпретацию и оценку информации. Всё это можно назвать составными частями многоаспектного анализа текста.
- Схема лингвистического анализа текста
- Основные характеристики, которые могут быть проанализированы в тексте
- Пример лингвистического анализа текста
- Текст
- Анализ
- Эффективный семантический анализ текста. Полное руководство
- Сервисы для семантического анализа
- Параметры анализа
- Резюмируя все вышесказанное
- Как сделать семантический анализ текста + пример SEO анализа
- Онлайн-сервисы семантического и SEO-анализа текста
- Водность текста
- Классическая тошнота документа
- Академическая тошнота текста
- Семантическое ядро
- Частота слов в семантическом ядре
- Как доработать текст
- Что такое семантический анализ текста
- Что значит термин «семантика»
- Сложность выполнения семантического анализа
- Применение семантического анализа для продвижения в поисковиках
- Статистические показатели
- Как провести семантический анализ
- Семантический анализ текстов. Основные положения
Схема лингвистического анализа текста

Что же представляет собой анализ текста? «Анализ» от древнегреческого «разложение, расчленение» предполагает изучение частей, из которых состоит текст. Выбор этих частей и направление анализа зависит от того, какие цели ставит перед собой исследователь.
Если мы хотим изучить форму, структуру текста, его языковые особенности, то это будет лингвистический анализ текста. Если мы сосредоточим наше внимание на лексике и фразеологии, то это будет лексико-фразеологический анализ.
Разбор текста с точки зрения его содержания и формы в их единстве – целостный или комплексный анализ, который является заданием олимпиады по литературе. И так далее.
Основные характеристики, которые могут быть проанализированы в тексте
- Общие стилистические особенности данного текста:
- Жанровые особенности текста
- Лексические средства выразительности
- Средства художественной выразительности, характерные для художественного и публицистического стилей
- Фонетический уровень – звуковые образные средства
- Морфологические средства выразительности
- Синтаксические средства выразительности
Пример лингвистического анализа текста
Лингвистический анализ произведения или текста проводится с целью изучения формы, структуры текста, а также его языковых особенностей.
Проводится на уроках русского языка и показывает уровень понимания смысла и видения особенностей языковой организации текста учеником, а также способность учащегося изложить собственные наблюдения, степень владения теоретическим материалом, терминологией.
В качестве примера проведем лингвистический анализ отрывка повести Ричарда Баха «Чайка по имени Джонатан Ливингстон».
Текст
Он почувствовал облегчение оттого, что принял решение жить, как живет Стая. Распались цепи, которыми он приковал себя к колеснице познания: не будет борьбы, не будет и поражений. Как приятно перестать думать и лететь в темноте к береговым огням.
- – Темнота! – раздался вдруг тревожный глухой голос. – Чайки никогда не летают в темноте! Но Джонатану не хотелось слушать. «Как приятно, – думал он. – Луна и отблески света, которые играют на воде и прокладывают в ночи дорожки сигнальных огней, и кругом все так мирно и спокойно…»
- – Спустись! Чайки никогда не летают в темноте. Родись ты, чтобы летать в темноте, у тебя были бы глаза совы! У тебя была бы не голова, а вычислительная машина! У тебя были бы короткие крылья сокола!
Там, в ночи, на высоте ста футов, Джонатан Ливингстон прищурил глаза. Его боль, его решение – от них не осталось и следа.
Короткие крылья. Короткие крылья сокола! Вот в чем разгадка! «Какой же я дурак! Все, что мне нужно – это крошечное, совсем маленькое крыло, все, что мне нужно – это почти полностью сложить крылья и во время полета двигать одними только кончиками. Короткие крылья!»
Он поднялся на две тысячи футов над черной массой воды и, не задумываясь ни на мгновение о неудаче, о смерти, плотно прижал к телу широкие части крыльев, подставил ветру только узкие, как кинжалы, концы, – перо к перу – и вошел в отвесное пике.
Ветер оглушительно ревел у него над головой. Семьдесят миль в час, девяносто, сто двадцать, еще быстрее! Сейчас, при скорости сто сорок миль в час, он не чувствовал такого напряжения, как раньше при семидесяти, едва заметного движения концами крыльев оказалось достаточно, чтобы выйти из пике, и он пронесся над волнами, как пушечное ядро, серое при свете луны.
Он сощурился, чтобы защитить глаза от ветра, и его охватила радость. «Сто сорок миль в час! Не теряя управления! Если я начну пикировать с пяти тысяч футов, а не с двух, интересно, с какой скоростью…»
Благие намерения позабыты, унесены стремительным, ураганным ветром. Но он не чувствовал угрызений совести, нарушив обещание, которое только что дал самому себе. Такие обещания связывают чаек, удел которых – заурядность. Для того, кто стремится к знанию и однажды достиг совершенства, они не имеют значения.
Анализ
Текст представляет собой отрывок из повести Ричарда Баха «Чайка по имени Джонатан Ливингстон». Этот эпизод можно назвать «Радость познания», так как в нём идёт речь о том, как главный герой изучает на себе возможности управления в полёте на большой скорости. Тип речи – повествование, стиль художественный.
Текст можно разделить на 4 микротемы: решение смириться и быть как все, озарение, проверка догадки, радость открытия.
Связь между предложениями параллельная, смешанная, в последнем абзаце – цепная. Структура текста подчинена раскрытию основной мысли: только тот, кто стремится к знанию, может достичь совершенства и испытать настоящее счастье.
Первая часть фрагмента – когда главный герой принял решение быть как все – неторопливая и спокойная. Словосочетания «почувствовал облегчение», «приятно перестать думать», «жить, как живёт Стая», «мирно и спокойно» создают впечатление правильности принятого решения, «распались цепи» – он свободен… От чего? «Не будет борьбы, не будет и поражений». Но это значит, не будет и жизни? Эта мысль не озвучена, но она напрашивается, а в тексте возникает тревожный глухой голос.
Его речь – восклицательные предложения, в которых напоминание Джонатану: «Чайки никогда не летают в темноте! Родись ты, чтобы летать в темноте, у тебя были бы глаза совы! У тебя была бы не голова, а вычислительная машина! У тебя были бы короткие крылья сокола!» Здесь автор использует глаголы в условном наклонении, причём в одном случае форма повелительного наклонения в значении условного – родись ты, то есть если бы ты родился. Но упоминание о крыльях сокола приводит главного героя к догадке – и скорость повествования резко меняется.
Бессоюзное сложное предложение «Его боль, его решение – от них не осталось и следа» рисует мгновенную смену событий.
Оба простых предложения в составе этого сложного являются односоставными: первое – назывное, второе – безличное. От статичности, неподвижности принятого решения – к молниеносному движению, которое происходит как будто без участия главного героя, помимо его воли, само по себе – поэтому и предложение безличное.
В этой микротеме трижды повторяется словосочетание «Короткие крылья!» – это и есть озарение, открытие, которое пришло к Джонатану.
И дальше – само движение, скорость растёт, и подчёркивается это градацией: не задумываясь ни на мгновение о неудаче, о смерти, семьдесят миль в час, девяносто, сто двадцать, еще быстрее! Это – момент наивысшего напряжения в тексте, которое заканчивается победой главного героя: «едва заметного движения концами крыльев оказалось достаточно, чтобы выйти из пике, и он пронесся над волнами, как пушечное ядро, серое при свете луны».
Последняя часть текста – радость победы, радость познания. Автор возвращает нас к началу, когда Джонатан решил быть как все, но теперь «Благие намерения позабыты, унесены стремительным, ураганным ветром».
Здесь опять используется градация, рисующая вихрь радости и ликования в душе героя. Он нарушает обещание, прозвучавшее в начале текста, но «Для того, кто стремится к знанию и однажды достиг совершенства», такие обещания не имеют значения.
В тексте используются профессионализмы из речи лётчиков, которые помогают автору раскрыть смысл происходящего: полёт, крылья, высота в футах, скорость в милях в час, отвесное пике, управление, пикировать.
Присутствуют метафоры, придающие поэтичность и возвышенность произведению:
- «Колесница познания»,
- «Ветер оглушительно ревел у него над головой»,
- «Луна и отблески света, которые играют на воде и прокладывают в ночи дорожки сигнальных огней».
Крылатое выражение «благие намерения» вызовет множество ассоциаций у внимательного читателя и заставит задуматься над тем, что главный герой не предавался намерениям – он действовал!
Сравнения:
- «он пронесся над волнами, как пушечное ядро»,
- «подставил ветру только узкие, как кинжалы, концы», – помогают ярче представить действие и признак.
В тексте имеются и контекстуальные антонимы:
- «тревожный глухой голос» – «приятно»,
- «всё так мирно и спокойно», «не голова, а вычислительная машина».
Особую роль в рассматриваемом фрагменте играют восклицательные предложения.
Если их выписать и прочитать отдельно от текста, мы получим сжатое и очень эмоциональное содержание всего эпизода: «Темнота! Чайки никогда не летают в темноте! Спустись! Родись ты, чтобы летать в темноте, у тебя были бы глаза совы! У тебя была бы не голова, а вычислительная машина! У тебя были бы короткие крылья сокола! Короткие крылья сокола! Вот в чем разгадка! Какой же я дурак! Короткие крылья! Семьдесят миль в час, девяносто, сто двадцать, еще быстрее! Сто сорок миль в час! Не теряя управления!»
Автор сумел передать в эпизоде основную идею всей повести «Чайка по имени Джонатан Ливингстон» – только тот, кто не боится быть не таким, как все, и идёт за своей мечтой вопреки всему, сможет быть по-настоящему счастливым сам и сделать счастливыми других.
Эффективный семантический анализ текста. Полное руководство
Семантика — наука, которая изучает связи слов в тексте между собой и общую его смысловую нагрузку. Исходя из этого, семантический анализ — это анализ основных статистических показателей текста, на основе которых определяется качество статьи и перспектива ее восприятия поисковой системой. От того, насколько качественно проведен такой анализ, зависит место текста в поисковой выдаче и попадет ли он вообще туда. Зачастую, с точки зрения семантики и полезности для пользователя, именно качественно построенной статьи достаточно, чтобы выйти в ТОП по нужным запросам поисковых систем.
В этой статье мы обговорим, из каких параметров состоит семантика текста, и как правильно ее проанализировать, чтобы довести статью до идеала.
Сервисы для семантического анализа
Чтобы получить все нужные параметры текста, нужно воспользоваться сторонними сервисами. Их представлено достаточно много, но все они работают по одним алгоритмам, поэтому результаты будут крайне похожи.
Параметры анализа
Чтобы проверить текст, необходимо скопировать его в соответствующее окно и запустить проверку. Мы получим таблицу с данными, на основе которых и будем проводить анализ и вносить необходимые правки.
Разберем по блокам ту информацию, которую получаем из сервиса.
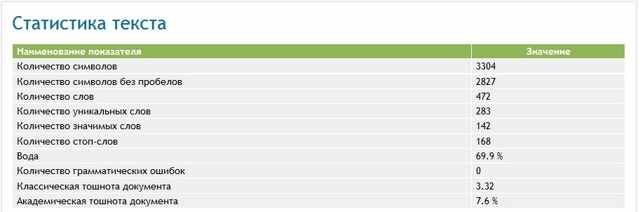
Размеры текста в символах и словах для нас не имеют особого значения. Здесь важно понимать, что статья должна быть такого размера, чтобы полностью ответить на ключевой запрос пользователя. Нас интересуют все параметры от «вода» включительно и далее.
Вода — процентный показатель количества слов, которые не относятся к теме текста. То есть не имеют для его содержания никакого значения. Абсолютно «сухой» текст не будет удобен для чтения пользователем. Слишком водный будет считаться поисковыми системами, как малоинформативный.
Поэтому нужно придерживаться золотой середины. В каждой тематике эта середина будет своя. В тексте о путешествиях водность в 70% будет нормой, в то время как в статье о программировании 30% уже будет много. Обычно, если вода более 70%, то стоит уменьшать ее всеми доступными способами.
Классическая тошнота документа определяет вхождение самого частого слова в отношении всего текста.
Слишком высокая тошнота будет считаться поисковой системой как переспам по ключевому слову, и может привести к исключению страницы из поиска. Отличной классической тошнотой считается показатель около 4-5%. Уменьшить или увеличить этот процент можно регулировкой вхождения этого самого повторяющегося слова.
Академическая тошнота также, как и параметр классической тошноты, является важной для определения релевантности текста. Она измеряет частоту повторения всех слов в тексте. Слишком низкий процент определяется ПС как «текст не о чем», то есть не релевантный. Слишком высокий — переспамом. Чтобы понимать, как отрегулировать тошноту в нужных нам пределах, перейдем ко второму блоку.
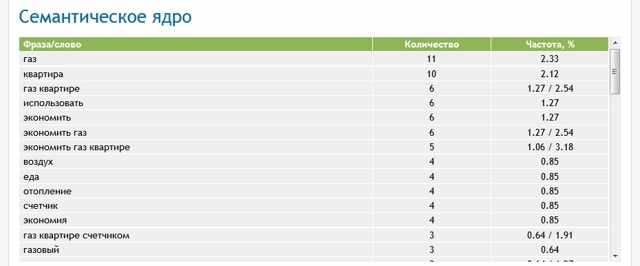
Второй блок показывает частоту вхождения всех слов и фраз в текст. Это и есть его семантическое ядро.
Идеальным можно считать такой текст, где главные для продвижения ключевые слова стоят на первых позициях и формируют определяемые фразы.
На приведенном выше примере практически идеальное расположение слов (сам текст в примере рассказывает о способах экономии газа в квартире, где есть счетчик).
Процентное вхождение ключевых слов для современных алгоритмов поисковых систем считается отличным, если находится в пределах 2-4%. Этого достаточно для Google и Яндекс и не будет считаться переспамом. У менее популярных ПС несколько другие градации спамности текста, и их нужно учитывать при продвижении под конкретную ПС.
Также важно наличие слов из тематики статьи, которые будут идти по частотности сразу после основных ключей. Это увеличивает релевантность. ПС точно понимают, что содержание текста целиком будет отражать ключевой запрос пользователей.
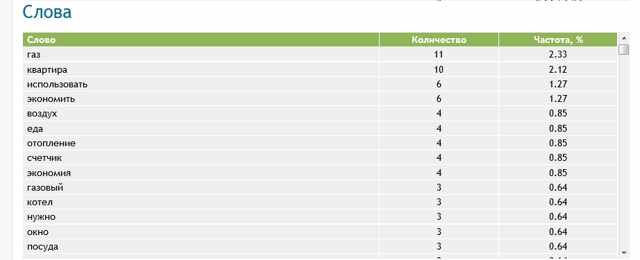
Третий блок содержит список вхождений всех слов. Используя этот список, можно отрегулировать тошноту, увеличивая или уменьшая количество нужных слов.
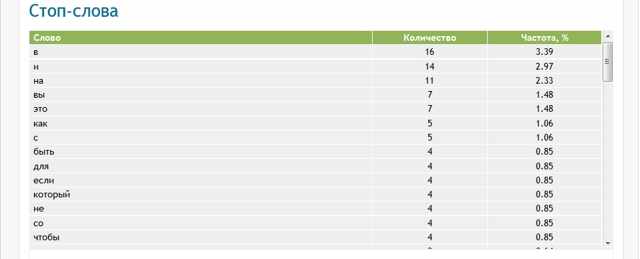
В последнем блоке содержится информация обо всех стоп-словах. Стоп-слова — это незначимые слова, которые не учитываются в поисковых запросах и для поисковой системы не имеют никакого значения.
Большое их количество ухудшает релевантность, но они играют важную роль в читабельности текста.
Здесь также нужно придерживаться золотой середины и исключить те, от которых содержание и удобство чтения не пострадают.
Резюмируя все вышесказанное
Семантический анализ текста проводится для устранения всех ошибок в его оптимизации и создания идеальной с точки зрения ПС страницы.
Придерживаться стоит таких параметров:
- Вода — 40-70%. Выше для гуманитарных текстов, ниже для технических.
- Классическая тошнота — до 4-5%.
- Академическая тошнота — до 9%.
- Вхождения ключевых слов — в пределах 2-4%.
Как сделать семантический анализ текста + пример SEO анализа
Семантический анализ текста показывает, из каких слов и словосочетаний состоит контент и какие из них встречаются чаще всего.
Преимущественно его используют для SEO-текстов с ключевыми словами и LSI-шлейфами: анализ позволяет примерно представить, как на контент отреагирует поисковая система.
Но не всегда цифры бывают понятны, а результат правок по советам семантического анализа — хорошим. Мы расскажем, как сделать анализ, на что обратить внимание и что делать с показателями. Кстати, в качестве примера для разбора мы будем использовать анализ статьи о вебинарах из нашего блога.
Онлайн-сервисы семантического и SEO-анализа текста
Advego. Семантический анализ от биржи контента Адвего — один из самых популярных сервисов у SEO-специалистов. Он бесплатен, доступен всем незарегистрированным и зарегистрированным пользователям. Показывает:
- Академическую тошноту,
- Классическую тошноту,
- Количество стоп-слов,
- Показатель «воды»,
- И другие менее значимые параметры.

Istio. Это — сервис, разработанный специально для семантического анализа текста. Доступен всем, регистрация не обязательна. Не требует оплаты подписки. Показывает:
- Показатель водности,
- Тошноту,
- Топ-10 самых используемых слов,
- Тематику текста,
- Другие параметры.
Miratext. Это — еще один сервис от биржи копирайтинга. Тоже бесплатный, доступный зарегистрированным и незарегистрированным пользователям. Показывает:
- Тошноту,
- «Водянистость»,
- Качество по закону Ципфа,
- Облако частотности слов,
- Другие менее значимые цифры.
 Проверка текста на уникальность
Проверка текста на уникальность
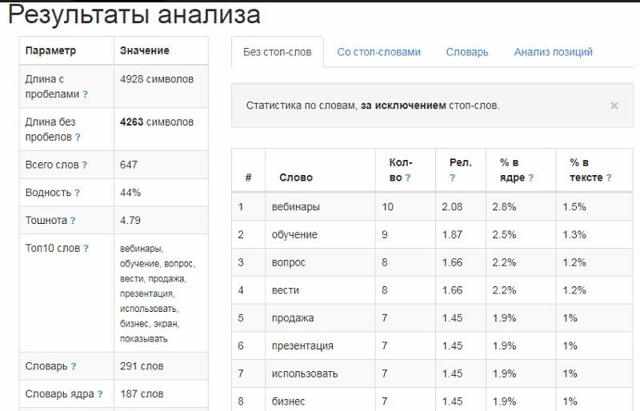
Давайте разберем показатели на примере анализа текста по семантическому анализатору от Адвего. Первые несколько строк — количество знаков с пробелами и без, количество слов, уникальных и значимых слов — не так важны. Важны следующие показатели:
- Вода — 67,7%,
- Классическая тошнота документа — 4,12%,
- Академическая тошнота документа — 8,7%,
- Семантическое ядро,
- Частота слов в семантическом ядре.
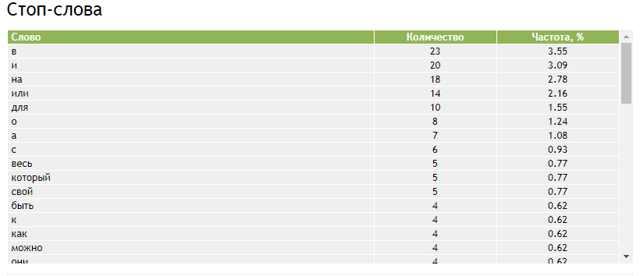
Водность текста
Семантический анализатор Адвего показывает самую высокую водность — на других сервисах при проверке нашего текста она 44% и 5%. Показатель водности — это соотношение незначимых слов к общему количеству слов. Чем больше в тексте стоп-слов, не несущих смысловой нагрузки, тем выше процент воды.
Слова, которые сервис считает «водой», выводятся в отдельной таблице «Стоп-слова». Чаще всего в нее попадают предлоги и местоимения. Кстати, нормальный показатель, упомянутый в описании семантического анализа по Адвего — 55-75%. Значит, в нашем тексте уровень воды нормальный.
Классическая тошнота документа
Она рассчитывается по самому частотному слову, как квадратный корень из количества его вхождений. Другие сервисы проверки используют подобный алгоритм, поэтому их «тошноту» можно приравнять к показателю «классическая тошнота» на Адвего.
Определенные нормы по классической тошноте в описании анализатора не указаны. Создатели лишь рассказали, что она зависит от длины текста — например, для статьи длиной в 20 000 символов тошнота 5% нормальная, а для заметки в 1 000 символов — слишком высокая. Многие агентства и SEO-специалисты придерживаются мнения, что тошнота не должна быть выше 4-6%.
Академическая тошнота текста
Она определяется как соотношение самых частотных и значимых слов ко всему тексту. Саму формулу подсчета не раскрывают.
В описании указано, что нормальный процент академической тошноты — 5-15%. Это косвенно подтверждено самим Яндексом: в его блоге привели пример переоптимизированного текста, и академическая тошнота этой заметки составила 19%. На практике многие SEO-специалисты требуют писать статьи с тошнотой не больше 10%.
Семантическое ядро
Блок семантического ядра показывает самые часто встречающиеся слова в тексте. Именно они задают тематику материала. Поэтому на первом месте должны быть слова, релевантные теме — иначе поисковая система не поймет, о чем вы пишете, и понизит сайт в выдаче или вообще не будет показывать страницу по нужным ключевым словосочетаниям.
В нашем примере в семантическом ядре на первом месте стоит слово «вебинар». Понятно, что статья о вебинарах — это подтверждают следующие позиции ядра из тематических слов.
Частота слов в семантическом ядре
Этот показатель рассчитывается по самым распространенным в тексте словам. Чем выше процент — тем чаще встречается слово. Этот показатель тесно связан с процентом самой тошноты.
В описании семантического анализа Адвего нет рекомендуемых параметров. Многие SEO-специалисты и агентства требуют не превышать показатель в 3-4%. А в переоптимизированной заметке Яндекса максимальная частота слова в семантическом ядре превысила 8%.
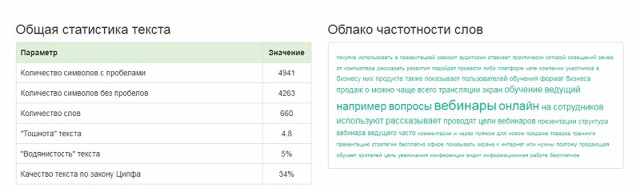
В Istio также показывают семантическое ядро, а в анализаторе Miratext его заменяет облако слов. Самые часто встречающиеся слова написаны крупным шрифтом. Семантический анализ Miratext также показывает качество текста по Ципфа.
Точный алгоритм анализа по Ципфа неизвестен, но его создатели утверждают, что он проверяет «естественность» текста, а нормальный показатель начинается от 50%. Проверка нашего текста на анализаторе выдала показатель в 34%. А при проверке на самом сервисе Ципфа — 77%.
Поэтому на эту строчку при проверке на Miratext.ru можно не обращать внимания — цифры не совпадают.
Как доработать текст
Если показатели вашего текста не совпадают с рекомендуемыми параметрами, его желательно доработать. Сделать это просто, и мы подготовили небольшую шпаргалку:
- Если «вода» высокая, удалите малозначимые слова и словосочетания, переформулируйте предложения так, чтобы в них встречалось меньше предлогов, если показатель низкий, разбавьте текст или не трогайте его
- Если классическая тошнота высокая, удалите несколько вхождений самого часто встречающегося слова, если низкая — добавьте вхождения ключевых слов
- Если академическая тошнота текста высокая, удалите несколько вхождений ключевых слов, если низкая — добавьте вхождения главного ключа
- Если в семантическом ядре находятся нетематические слова, добавьте в текст вхождения ключей и других тематических слов
- Если частота слов в семантическом ядре слишком высокая, удалите несколько вхождений
Не забывайте о том, что в первую очередь текст должен нравиться людям. Поэтому не стоит воспринимать семантический анализ текста как истину в последней инстанции — даже далеко не идеальные в плане SEO статьи попадают в топ. Например, в первой в выдаче по запросу «что такое инфляция» статье показатель воды по Адвего приближается к верхней планке, составляет 72,6%.
А на странице со второго места показатель академической тошноты превышает рекомендованную многими SEO-специалистами отметку в 10%, а частота слова в семантическом ядре превысила 5%.
Если текст интересный, полезный, структурированный, но немного не соответствует рекомендуемым показателям, можете оставить все как есть.
Что такое семантический анализ текста
 Семантический анализ позволяет определить самые важные ключевые слова, фразы, отображающие в полной мере основы деятельности организации, что помогает грамотно сформировать семантическое ядро и привлечь целевую аудиторию.
Семантический анализ позволяет определить самые важные ключевые слова, фразы, отображающие в полной мере основы деятельности организации, что помогает грамотно сформировать семантическое ядро и привлечь целевую аудиторию.
Что значит термин «семантика»
Чтобы лучше разобраться в том, что такое семантический анализ, сначала следует выяснить значение слова «семантика».
Семантика – это дисциплина, которая изучает связь слов между собой и человеческой реальностью, определяет зависимость значения слова от контекста фразы.
Семантическая модель включает слово, его определение, сочетания с другими словами, составление из него фраз и предложений.
Сложность выполнения семантического анализа
Семантический анализ – трудная математическая задача, решение которой применяется в процессе создания искусственного интеллекта, при этом усложняется необходимостью обработки естественного языка.
Сложность заключается в том, что компьютер не умеет правильно объяснять образы, которые человек передает с помощью символов.
Данные качественного семантического анализа могут использоваться в торговле для анализа спроса на товары по полученным отзывам, в поисковиках, системах автоматического перевода и пр.
Возьмем, к примеру, предложение «женщина вошла в кафе с черной сумкой». Здесь можно рассматривать два варианта связи – женщина с сумкой или кафе с сумкой. Человек понимает, что этот аксессуар традиционно принадлежит именно женщине, а не заведению, тогда как машина разницы не видит.
Применение семантического анализа для продвижения в поисковиках
Семантический анализ текста оценивает количество слов или фраз, которые определяют смысл текста, то есть его семантическое ядро, и статистические показатели. Правильно сформированное семантическое ядро способно быстро продвигать статью в поисковой системе.
Комбинируя слова, составляя грамотно фразы, можно создать текст, который будет эффективно воздействовать на читателя, побуждая его к тем действиям, в которых заинтересованы владельцы сайта.
Поисковые системы также выполняют семантический анализ, определяя смысл текста, впоследствии чего в ответ на запрос предлагают выбранные материалы.
Статистические показатели
К статистическим показателям относятся: количество символов с пробелами и без, количество слов, в том числе уникальных и значимых, стоп-слов, количество воды, грамматических ошибок, процент классической и академической тошноты, семантическое ядро.
При подсчете учитывается число уникальных слов (без повторений), число значимых слов (существительных), стоп-слов (которые лишены своего смысла). Процент воды определяется путем деления числа значимых слов на общее количество. Количество воды нельзя считать показателем качества текста, но все же лучше, чтобы этот показатель не превышал 65%.
Если в тексте обнаружено 75% воды и больше, стоит уменьшить число незначимых слов. Классическая тошнота определяет, сколько раз повторяется в тексте одно и то же слово. Оптимальное значение классической тошноты – 7. Повышение данного показателя приводит к торможению продвижения сайта.
Коэффициент академической тошноты указывает на повторение большого количества слов в тексте. Соответственно, увеличение плотности ключевых слов приводит к его повышению.
Как провести семантический анализ
Семантический анализ текста можно быстро выполнить в Интернете — такая функция предлагается на Адвего, Txt, Istio и др. Но необходимо учитывать следующее: хотя программы и обладают стандартным алгоритмом, результаты могут немного отличаться.
Семантический анализ текстов. Основные положения
Семантический (смысловой) анализ текста – одна из ключевых проблем как теории создания систем искусственного интеллекта, относящаяся к обработке естественного языка (Natural Language Processing, NLP), так и компьютерной лингвистики.
Результаты семантического анализа могут применяться для решения задач в таких областях как, например, психиатрия (для диагностирования больных), политология (предсказание результатов выборов), торговля (анализ “востребованности” тех или иных товаров на основе комментариев к данному товару), филология (анализ авторских текстов), поисковые системы, системы автоматического перевода и т.д.
Несмотря на свою востребованность практически во всех областях жизни человека, семантический анализ является одной из сложнейших математических задач. Вся сложность заключается в том, чтобы “научить” компьютер правильно трактовать образы, которые автор текста пытается передать своим читателям/слушателям.
Способность “распознавать” образы считается основным свойством человеческих существ, как, впрочем, и других живых организмов. Образ представляет собой описание объекта. В каждое мгновение нашего бодрствования мы совершаем акты распознавания. Мы опознаем окружающие нас объекты и в соответствии с этим перемещаемся и совершаем определенные действия.
Мы можем заметить в толпе друга и понять, что он говорит, можем узнать голос знакомого, прочесть рукопись и идентифицировать отпечатки пальцев, можем отличить улыбку от злобной гримасы.
Человеческое существо представляет собой очень сложную информационную систему – в определенной степени это определяется чрезвычайно развитыми у человека способностями распознавать образы.
Естественный язык в отличие, например, от компьютерных (алгоритмических) языков формировался во многом стихийно, не формализовано.
Это обуславливает целый ряд сложностей в понимании текста, вызванных, например, неоднозначным толкованием одних и тех же слов в зависимости от контекста, который может быть и неизвлекаем, в принципе, из самого текста. Следовательно, этот контекст или знание о предметной области в систему должны быть заранее внесены.
К тому же зачастую практические задачи требуют точного определения времени, места того, что описано в тексте, точной идентификации людей и т.д., в то время как подобная информация находится за пределами данного текста.
В этом случае система может или не обрабатывать эту информацию, или оставить ее до выяснения контекста и даже попытаться проявить инициативу в выяснении контекста, например, в диалоге с оператором, задающим ввод текста. То, как ведет себя система в подобной ситуации, определяется стилем и схемой работы системы.
Промышленные системы автоматической обработки текста, в основном, сейчас используют два этапа анализа текста: морфологический и синтаксический. Однако теоретические разработки многих исследователей предполагают существование следующего за синтаксическим этапа – семантического.
В отличие от предыдущих шагов семантический этап использует формальное представление смысла составляющих входной текст слов и конструкций. Суть семантического анализа понимается разными исследователями по-разному.
Многие ученые сходятся во мнении, что в сферу семантического анализа входит:
- Построение семантической интерпретации слов и конструкций,
- Установление содержательных семантических отношений между элементами текста, которые уже принципиально не ограничены размером одного слова (могут быть больше или меньше одного слова).
Некоторые ученые предлагают рассматривать не просто текст на основе его составляющих слов, предложений, абзацев, но и попытаться выявить тот смысловой образ, который автор хотел создать в сознании своих читателей, посредством этого текста. На современном этапе развития искусственного интеллекта эта задача является практически неразрешимой.
Основные проблемы понимания текста в обработке естественных языков таковы:
- Знание системой контекста и проблемной области и обучение этому системы. Например, из предложения «мужчина вошел в дом с красным портфелем» можно извлечь как представление о мужчине с красным портфелем, так и о доме с красным портфелем, если заранее не иметь в виду, что применительно к мужчинам употребление принадлежности портфеля гораздо вероятнее, чем применительно к дому.
- Различная форма передачи синтаксиса (т.е. структуры) предложения в разных языках. Например, если синтаксическая роль слова (подлежащее, сказуемое, определение и т.д.) в английской речи во многом определяется положением слова в предложении относительно других слов, то в русском предложении существует свободный порядок слов и для выявления синтаксической роли слова служат его морфологические признаки (например, окончания слов), служебные слова и знаки препинания.
- Проблема равнозначности. Предложения «длинноухий грызун бросился от меня наутек» и «заяц бросился от меня наутек» могут означать одно и то же, но могут иметь и разный смысл, например, если в первом случае имелся в виду длинноухий тушканчик.
- Наличие в тексте новых для компьютера слов, например неологизмов.
Самообучаемая система должна уметь «интуитивно» определить (возможно, и неправильно, но с возможность в дальнейшем исправить себя) лексическую роль, морфологическую форму этого слова, попробовать вписать его в существующую структуру знаний, наделить его какими-то атрибутами или выяснить все это в диалоге с оператором. Система, не способная к самообучению просто потеряет какое-то количество информации.
- Проблема совместимости новой информации с уже накопленными знаниями. Новая информация может каким-то образом противоречить уже накопленной информации. Необходимо реализовать механизм, определяющий, в каких случаях нужно отвергнуть старую информацию, а в каких – новую.
- Проблема временных противоречий. Так в предложении «я думал, что сверну горы» глагол в прошедшей форме «думал» сочетается с глаголом будущего времени «сверну».
- Проблема эллипсов, то есть предложений с пропущенными фактически, но существующими неявно благодаря контексту словами. Например, в предложении «я передам пакет тебе, а ты – Ивану Петровичу» во второй части опущен глагол «передашь» и существительное «пакет».
Системы, направленные на извлечение знаний из текстов на естественных языках (то есть на таких языках, на которых общаются люди в отличие, например, от алгоритмических языков), а также на синтез текста на основе знаний называются лингвистическими трансляторами или лингвистическими процессорами.
Подобные системы могут интегрироваться с экспертными системами, то есть системами, служащими для того, чтобы заменять человека-эксперта в какой-либо области, например медицинская диагностика, юридическое консультирование, бизнес-планирование, диагностика различных технических неисправностей и многих других. В этом случае экспертная система с одной стороны имеет возможность высокоэффективно обучаться, накапливать новые знания, а с другой стороны, способна выдавать информацию пользователю в максимально удобной форме.
Кроме того, лингвистический процессор может быть интегрирован с системой распознавания и (или) синтеза речи, что может сделать процесс общения с компьютером максимально удобным, а, следовательно, и продуктивным.
Одной из наиболее очевидных направлений применения лингвистических процессоров является машинный перевод с одного естественного языка (ЕЯ) на другой.
Также подобные системы могут использоваться и используются для автоматического пополнения информационных баз и баз знаний (т.н. «data mining») в том числе путем сканирования Интернета.
В настоящее время существуют различные подходы к созданию систем для автоматизированного семантического анализа.
Проведя поверхностный анализ отечественной и зарубежной литературы по способам и средствам семантического анализа текста, можно сделать следующие выводы.
Системы семантического анализа не могут существовать без морфологической составляющей. В качестве морфологической составляющей выступают различные виды словарей словоформ (т.е. содержащие все варианты склонения, спряжения и т.д. того или иного слова).
Самый популярный словарь (относительно русского языка) среди исследователей – грамматический словарь, предложенный Зализняком А.А. Данный словарь содержит около 100 000 словоформ, в то время как, по предварительным подсчетам, в русском языке существует более 200 000 слов.
Поэтому возникает проблема «неполноты» того или иного словаря. Существует ряд подходов для решения этой проблемы.
- Первый способ – это так называемое обучение с учителем, в качестве учителя выступает человек.
Например, когда система сталкивается со словом, отсутствующим в словаре, она прекращает свою работу и ждет от учителя, пока он покажет ей все варианты словоформ данного слова.
Этот вариант является очень трудоемким, потому что требует постоянного «обучения» со стороны человека к тому же, сильно увеличивается время выполнения анализа.
- Второй способ – обучение без учителя, на основе правил. В данном случае исследователи для проведения морфологического анализа используют обратные словари или, собственноручно созданные, базы аффиксов (т.е. суффиксов, префиксов, окончаний и т.д.) с указанием морфологических признаков, которым соответствует тот или иной аффикс.
Существует также подход, согласно которому нет необходимости создавать отдельную базу аффиксов, достаточно просто сравнить форму нового (отсутствующего в словаре слова) со всеми словами уже существующими в словаре и присвоение новому слову признаков, соответствующих словоформе слова из словаря с наибольшим «весом».
В данном случае используются статистические методы. У этого способа главным недостатком является его вероятностная часть – в зависимости от статистического метода, используемого теми или иными учеными, «правильность» определения морфологических признаков варьировалась от 50 до 97%.
Поэтому очень часто системы морфологического анализа используют гибридный метод, использующий оба этих подхода.
Следует упомянуть, что на этапе морфологического анализа некоторые системы используют также словари акронимов (аббревиатур) и словари личных имен, что существенно ускоряет сам процесс семантического анализа.
Системы семантического анализа не могут существовать без синтаксической составляющей. Основной задачей синтаксического анализа является построение синтаксического дерева предложения.
Также как и морфологический анализ, синтаксический анализ является предварительным этапом перед семантическим анализом. На этом этапе отсеивается большая часть омонимов (слова разного значения, но одинаково звучащие, напр., пол, коса, ключ), выявленных на этапе морфологического анализа. Что, в свою очередь, существенно ускорит семантический анализ.
Для представления в памяти компьютера значения всех содержательных единиц рассматриваемого языка (лексических, морфологических, синтаксических и словообразовательных) и приведения их к единому, формальному виду, понятному компьютеру, используется, специально созданный для этого искусственный язык или, как его еще называют некоторые ученые, метаязык.
Реально в качестве семантического метаязыка в большинстве современных работ используется не универсальный искусственный язык, а некий упрощенный и стандартизированный подъязык описываемого языка со своим словарем и грамматикой.
По замыслу, UNL – это искусственный семантико-синтаксический язык, предназначенный для описания, хранения и распространения информации в WWW в не зависящем от какого-либо естественного языка виде, а также независимо от конкретной компьютерной платформы или операционной системы.
В отличие от систем машинного перевода, призванных осуществлять перевод с одного естественного языка на другой, предполагается, что система UNL должна уметь автоматически (или полуавтоматически) преобразовывать исходный текст в его UNL-представление, а затем синтезировать из этого представления текст на нужном языке.
Таким образом, о UNL можно говорить как о своеобразном языке-посреднике, удобном для хранения информации и ее восстановления на любом естественном языке из числа поддерживаемых системой.
Кроме того, огромную популярность получили так называемые онтологии (формальные явные описания терминов предметной области и отношений между ними), которые могут быть использованы как основа для семантического анализа. Во всемирной паутине онтологии стали обычным явлением.
Онтологии варьируются от больших таксономий, категоризирующих веб-сайты (как на сайте Yahoo!), до категоризаций продаваемых товаров и их характеристик (как на сайте Amazon).
Консорциум WWW (W3C) разрабатывает RDF (Resource Description Framework), язык кодирования знаний на веб-страницах, для того, чтобы сделать их понятными для электронных агентов, которые осуществляют поиск информации.
Подводя итоги всему вышесказанному, можно сделать выводы, что семантический анализ в настоящее время движется в сторону формальных грамматик (Мельчук И., Хомский Н. и др.), но пока значительных прорывов в данной области не наблюдается.